开云·kaiyun「中国」体育官方网站 登录入口
开云·kaiyun「中国」体育官方网站 登录入口
What???
一直低调行事的国内初创公司,旗下模子暗暗地跃升成国内第一、全国第五(仅排在 o1 系列和 Claude 3.5 之后)!
而且是前十名中的唯独一家国产公司。
(该榜上国产第二名是阿里开源的 qwen2.5-72b-instruct,总榜第 13)。
而且它登上的这个排名榜 LiveBench,固然当今还莫得大模子竞技场(LMSYS Chatboat Arena)那么广为东说念主知,但经验杠杠的——
图灵奖得主、Meta 首席 AI 科学家杨立昆(Yann LeCun),聚会纽约大学等在本年 6 月推出。
堪称是"全球首个无法舞弊的 LLM 基准测试"。
而此次冷不防杀出来的黑马,其实相比闇练国内大模子竞争状况的一又友们还是猜到了——
Step 系列,背后是大模子六小虎之一的阶跃星辰。
提醒奴婢高分拿下全球第一
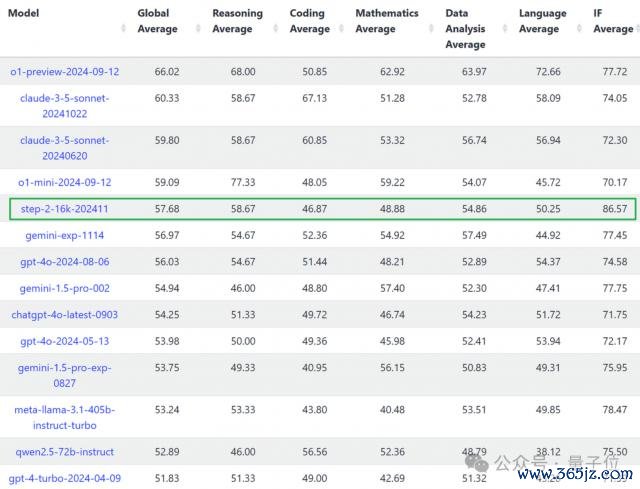
在 LiveBench 榜单上,阶跃星辰自研的万亿参数话语大模子 Step-2-16k-202411 在 Global Average 上拿下 57.68 分。
位列总榜第五、国产第一。
这个榜单之前出现频率不高,一方面是它如实很新,本年 6 月才刚推出;另一方面愈加执行,那即是此前国产大模子并未在这个榜单塔尖得到傲东说念主获利。
这倒也不磨叽榜单自己的实力——
LeCun 和纽约大学等机构联手推出,专为大模子蓄意,现时包含 6 个类别的 17 个不同任务,每月更新新问题。
指标是确保榜单的问题不易受到混浊 ,而况概况松弛、准确、平允地进行评估。
强调不易受到混浊,是因为锻真金不怕火数据中包含了精深互联网骨子,好多 BenchMark 很容易受到混浊。
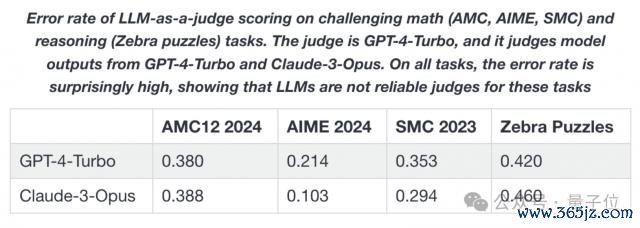
比如人人相比闇练的数学测试集 GSM8K,最近被解说有好些模子还是在它这儿过拟合了。这显明为评估模子智力带来了困扰。
除了要留心 BenchMark 被混浊,确保评估式样平允、无偏见也很蹙迫。
一般来说,人人齐摄取的是 LLM 担任评委或东说念主类当裁判这两种式样。而 LiveBench 聘请摄取客不雅、基技艺实判断来评估每个问题。
那么,当我们初度正视这个榜单的时候,我们还能从其中看出些什么?
先说获利出色的 Step-2。
IF Average 一项,也即是提醒奴婢,它以最高分拿下全球第一。
这个边幅的骨子,是对《卫报》近期新著作进行改写、简化、转头或生成故事。
86.57 这个获利是真是罕见高——榜单上其余世东说念主(哪怕是 OpenAI 和 Anthropic 家的模子们)齐在 70-80 分段,单项第二名的 Meta-LLaMA-3.1-405b-instruct-turbo 比它低了 8 分多。
这意味着,Step-2 在话语生成上对细节有强截止力,结实智力 max,然后更好地罢免东说念主类提醒。
更具体些不错结实为,当我们庸碌东说念主输入语句倒置、语意不清、表意依稀的非专科 · 真庸碌 · prompt 时,Step-2 能诱骗荆棘文、具体情境料想使用者的具体需求,把一个依稀提醒从" 360p "进行" 1080p "的结实,精确捕捉依稀提醒背后的信得过意图。
同期意味着骨子创作智力也很强,比如让它创作一首古诗词,它在字数、格律、押韵、境界等方面,齐能有精确的把控。
完全自主研发,MoE 架构,万亿参数
在此次因为 LiveBench 又出来炸场一波之前,Step-2 留给外界的最深远印象,一定有一个是"国内首个由初创公司推出的万亿参数大模子"。
这有点像阶跃作风的具像化。在大模子六小虎中,阶跃的 Step 系列发布最晚,但起初绝不无极。
本年 3 月,Step-2 在全球诱导者前卫大会开幕式预览亮相,一下子就从前作 Step-1 的千亿参数范围,拉升到了万亿参数范围。
吊足了胃口后,夏天的 WAIC 2024 时间,Step-2 推出郑再版。

模子摄取了 MoE 架构。
一般而言,主流锻真金不怕火 MoE 模子有两种式样,否则就基于已有模子通过 upcycle(朝上复用)运转锻真金不怕火,否则就重新运转锻真金不怕火。
Upcycle 式样所需算力相对更低、锻真金不怕火后果更高,但随应酬便就到这种式样的天花板了。
比如基于拷贝复制得到的 MoE 模子,罕见容易出现巨匠同质化严重的情况。
而聘请重新运转锻真金不怕火 MoE 模子的话,概况探得更高的模子上限,但手脚代价,锻真金不怕火难度也会增大。
但阶跃团队如故聘请了后者,聘请完全自主研发,聘请重新运转锻真金不怕火。

过程中,通过部分巨匠分享参数、异构化巨匠蓄意等立异 MoE 架构蓄意,Step-2 这个羼杂巨匠模子中的每个巨匠齐得到了充分锻真金不怕火。
故而,Step-2总参数目达到万亿级别,每次锻真金不怕火或推理所激活的参数目也高出了市面上的大部分 Dense 模子。
此外,Step-2 的锻真金不怕火过程中,阶跃的系统团队冲破了 6D 并行、极致显存处置、完全自动化运维等关键本事,解救起了整个模子的高效锻真金不怕火。
初亮相时,阶跃官方暗意:
Step-2 在数理逻辑、编程、中语常识、英文常识、提醒奴婢等方面体感全面靠拢 GPT-4。
诱骗此次 LiveBench AI 的获利来看,团队对 Step-2 的定位、上风场地,把抓得很明晰。
基座模子本事智力强,关键是要让东说念主用起来才行。
官方音讯是,Step-2还是接入了阶跃星辰的 C 端智能糊口助手「跃问」,Web 端和 App 齐不错试一把。
要是是诱导者,不错在阶跃星辰怒放平台通过 API 接入使用 Step-2。
话语模子和多模态模子透澈要
开篇我们提到,Step 模子是一个系列,而 Step-2 是其话语模子的实力代表。
在这个系列中,除了话语模子,阶跃星辰的多模态模子也很有看头。
Step-1.5V是阶跃星辰的多模结实大模子,这款模子在三个方面上风杰出:
一是感知智力。立异的图文混排锻真金不怕火要领,让 Step-1.5V 能结实复杂图表、进程图、准确感知物理空间复杂的几何位置,还概况处理高分辩率和极限长宽比的图像。
二是推奢睿力。凭据图像骨子进行各类高等推理任务,如解答数学题、编写代码、创作诗歌等。
三是视频结实智力。它不仅概况准确识别视频中的物体、东说念主物和环境,还概况结实视频的举座氛围和东说念主物情谊。
生成方面,阶跃手里有Step-1X 图像生成大模子。
Step-1X 摄取 DiT(Diffusion Models with transformer)架构,有 600M、2B 和 8B 三种不同的参数目,语意结实和图像创意齐全两手抓。
具体而言,不管文本提醒肤浅如故复杂,不管是画单一双象如故多线索、复杂内涵场景,它齐能 cover。
另外,该模子还解救针对中国元素的深度优化,使生成骨子更相宜国东说念主的审好意思作风。

至于话语模子和多模态模子透澈要,阶跃有我方的意旨真谛意旨真谛。
从建造一运转,阶跃星辰就明确了自己通往 AGI 的道路图:
单模态——多模态——多模态结实和生成的斡旋——全国模子—— AGI。
换言之,阶跃的指标是诱导出概况齐全 AGI 的多模态大模子,并欺诈这些自主研发的大模子,创造新一代的 AI 应用。
为着这个指标,这一年多来,阶跃还是写下了属于我方的谜底。
研发迭代速率很快,不到一年,非论 Step-1 到 Step-2, 如故 Step-1V 到 Step-1.5V,举座不绝跑步前进中。
居品也有我方的念念法,莫得局限在 ChatBot 上。Step-2 登顶国内的归拢天,阶跃旗下的跃问还上了一个新功能:
肤浅配置,就能通过 iPhone 16 右下方侧边的"相机截止"按钮,一键调用"拍照问"功能。
莫得 iPhone 16 的苹果用户,把系统升级到 iOS18 也能一要领用国产 AI 了。

固然还是在六小虎中占据一席,但近日看阶跃,仍然念念以黑马来描画它。
论本事和实力,Step-2 能俄顷杀到业界泰斗榜单国内第一,成为全球榜单前十唯独国产玩家。
大模子波澜奔腾于今,还是有快两年的时期了。
两年里,投身其中的本事从业者们齐在(看似漫步其实共同)打造一个愿景,一个好多东说念主齐振作参与并与之筹办在通盘的愿景。
有根由信服,阶跃 Step 系列,以及中国的大模子们,齐会因为超卓的本事实力和不懈的立异追求,越来越熠熠生辉。
One More Thing
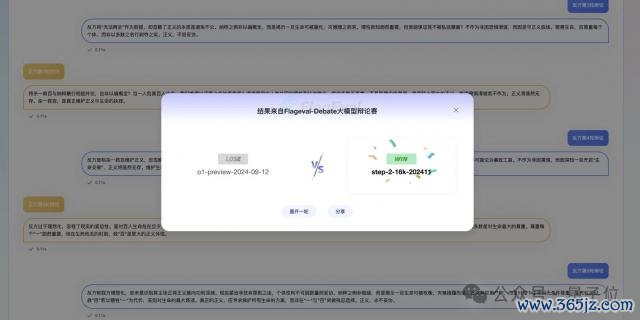
上个月,智源盘考院推出辩护平台 FlagEval Debate,旨在通过引入模子辩护这一竞争机制对大模子智力评估提供新的度量标尺。
和大模子竞技场玩法有点访佛,即是俩模子一个正方一个反方,双盲测试,辩护完后用户投票。
然后才揭晓正反两边齐是谁。
模子辩护,主要靠的是信息结实、常识整合、逻辑推理、话语生成和对话智力。
天然了,同期还能测复杂语境中信息的处理深度和移动应变智力,反馈其学习与推理的高出水平。
浅玩了一下,有些议题还蛮专诚旨真谛。
比如"博物馆着火,只可救一个,救猫如故救《蒙娜丽莎》"这个议题。
俩模子吵到背面,"猫有九条命"的话齐说出来了,笑死。

终末反复投了几次,Step-2 大捷 o1。
看来它辩护智力也很强呀……
榜单官网:https://livebench.ai/#/blog
跃问连气儿:https://yuewen.cn
FlagEval Debate 官网:https://flageval.baai.org/#/debate
— 完 —
点这里� � 关爱我,难忘标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿施展日日重逢 ~